
Penghapusan Data Berpasangan (Pairwise deletion)
Penghapusan berpasangan adalah alternatif untuk penghapusan daftar untuk mengurangi hilangnya data. Menggunakan penghapusan berpasangan, kasus apa pun dapat berkontribusi pada beberapa analisis tetapi tidak untuk yang lain tergantung pada apakah data yang dibutuhkan tersedia. Oleh karena itu untuk analisis Anda dalam contoh ini, semua kasus dengan data yang tersedia tentang usia dan afiliasi politik akan dimasukkan terlepas dari nilai yang hilang untuk variabel lain seperti jenis kelamin, pendapatan, atau pendidikan.
Pairwise Delection Adalah teknik yang paling banyak dilakukan dalam menangani data yang hilang dengan skor estimasi.
Pairwise deletion
membuang sepasang pengamatan yang mengandung data hilang. Metode ini berupaya untuk meminimalkan kehilangan yang muncul listwise deletion.
Cara yang mudah untuk memikirkan bagaimana metode ini bekerja yaitu memikirkan sebuah korelasi matriks. Sebuah korelasi mengukur kekuatan terhadap hubungan antara dua variabel. Untuk masing-masing pair pada variabel yang mana data tersedia. Koefisien korelasi akan mengambil data tersebut sehingga Pairwise Delection
memaksimalkan semua data yang ada dengan sebuah analisis dari basis analisis. sangat penting untuk mengerti sebagian besar kasus-kasus sebuah asumsi penting dalam menggunakan teknik ini adalah bahwa data yang kita miliki Adalah MCAR (missing completely atrandom). Dengan kata lainnya yaitu. Yang peneliti butuhkan untuk mendukung kemungkinan data yang hilang pada variable dependen mereka yaitu tidak dikaitkan pada variabel independen yang lain. Demikian pula pada variabel dependen itu sendiri.
Kelebihan dari pairwise deletion
- Meningkatkan kekuatan pada analisis
- Tetap menjaga sebangak mungkin kasus untuk masing-masing analisis
- Menggunakan semua informasi yang memungkinkan pada masing-masing analisis
kelemahan dari pairwise Delection
- Analisis tidak dapat dibandingkan karena sampel yang berbeda pada masing-masing waktu
- Standar eror dihitung melalui Software package menggunakan ukuran sampel rata-rata di seluruh analisis.
Contoh.
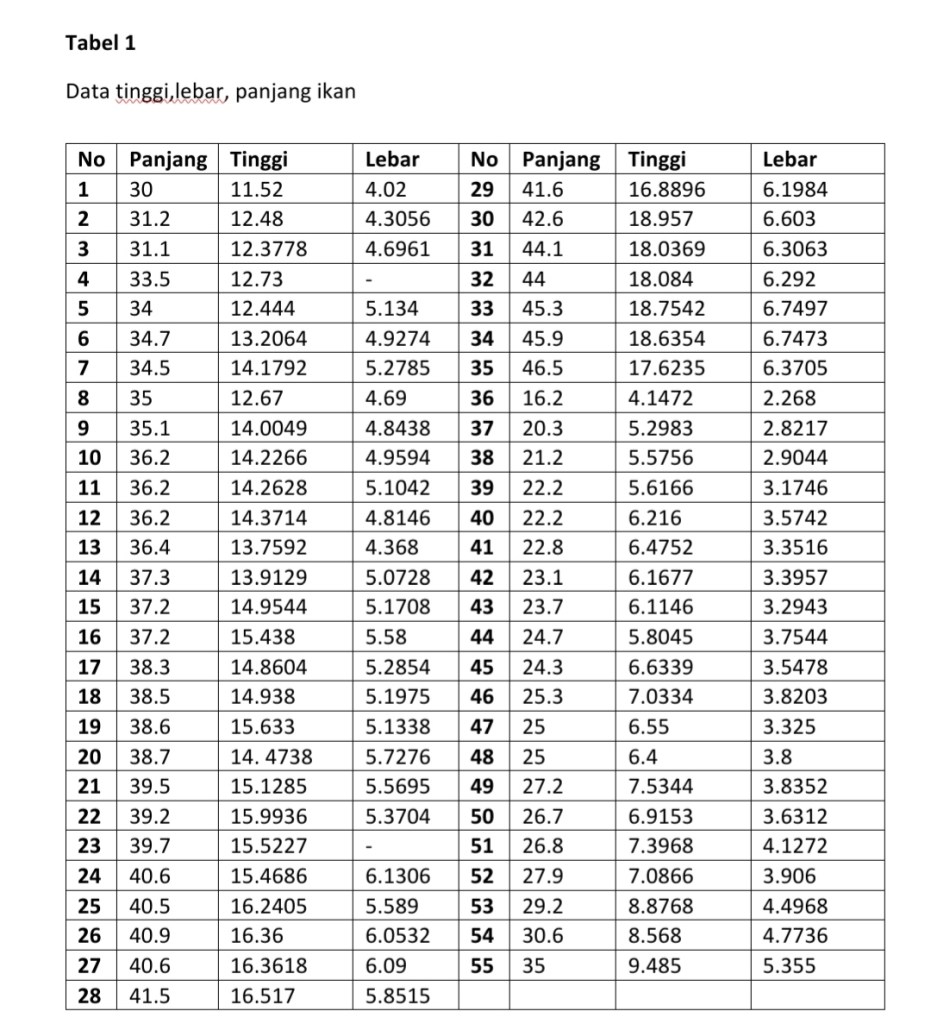
- Data tersebut Diimport ke dalam Software R dengan nama Dataikan
>Str(dataikan)
‘data.frame’: 55 obs. Of 3 variables:
$ Panjang: num 30 31.2 31.1 33.5 34 34.7 34.5 35 35.1 36.2… $ $Tinggi: num 11.5 12.5 12.4 12.7 12.4…
$ Lebar : num 4.02 4.31 4.7 NA 5.13 …
> Summary (dataikan)
Panjang Tinggi Lebar
Min. :16.20 Min. : 4.147 Min. :2.268
1st Qu.:26.75 1st Qu. : 7.060 1st Qu.:3.820
Median :35.00 Median :13.759 Median :4.927
Mean :33.49 Mean :12.097 Mean :4.781
3rd Qu.:39.35 3rd Qu. :15.496 3rd Qu.:5.580
Max. :46.50 Max. :18.957 Max. :6.750
NA’s :2
- Mengidentifikasi pengamatan data hilang dan data lengkap pada variabel ikan
>datahilang <- dataikan[is.na(dataikan$lebar),]
>datahilang
Panjang Tinggi Lebar
4 33.5 12.7300 NA
23. 39.7 15.5227 NA
>datalengkap <- dataikan[is.na(dataikan$lebar),]
>datalengkap
Panjang Tinggi Lebar
1 30.0 11.5200 4.0220
2 31.2 12.4800 4.3056
3 31.1 12.3778 4.6961
5 34.0 12.4440 5.1340
6 34.7 13.6024 4.9274
7 34.4 14.1795 5.2785
:
:
- Data ini peneliti tidak perlu mengambil data ke-4 dan ke-23 untuk analisis regresi antara variabel tinggi ikan terhadap variabel panjang dan lebar ikan. Dicontohkan pada model 1.1 menggunakan data lengkap.
- Data pada Model1.2 digunakan jika peneliti hanya ingin memodelkan regresi antara variabel tinggi ikan dengan variabel panjang ikan, maka seluruh pengamatan harus tetap digunakan menggunakan data awal dataikan
>Model.1 <- lm(Tinggi~.,data=datalengkap)
>Model.1
Call:
lm(formula = Tinggi ~ ., data = datalengkap)
Coefficient:
(Intercept) Panjang Lebar
-6.8976 0.6316 -0.4515
>Model.2 <- lm(Tinggi~Panjang,data=dataikan)
>Model.2
Call:
lm(formula = Tinggi ~ Panjang, data = dataikan)
Coefficient:
(Intercept) Panjang
-6.9112 0.5676
Metode ini menerapkan metode Penghapusan berpasangan dan menghasilkan hasil berupa
Model 1.1 untuk mengahasilkan hasil apabila semua variabel digunakan dalam analisis.
Berbeda dengan Model1.2 menggunakan data awal yaitu dataikan. Hasil dugaan koefisien regresi model 1.2 yaitu -6.9112 pada koefisien intersep dan 0.5676 pada koefisien panjang ikan.
Seperti pada permodelan dalan data ikan ini, meskipun penerapan sangat mudah dan sederhana tetapi penggunaan metode ini sangat tidak dianjurkan. Karena mengingat rekomendasi bahwa lebih baik digunakan pada data dengan mekanisme data hilang MCAR disertai dengan ukuran sampel yang cukup banyak. Sedangkan dalam kasus ini, data ini memiliki ukuran sampel sebanyak 55 pengamatan yang dapat dibilang cukup kecil dan data ini cenderung mengarah pada MAR.
- E-commerce dan E-business Pengertian, Contoh, KeuntunganE-COMMERCE E-commerce (perdagangan elektronik), adalah kegiatan jual beli barang/jasa atau transimisi dana atau data melalui jaringan elektronik, terutama internet. Secara umum e-commerce didefinisikan sebagai segala bentuk transaksi perdagangan/perniagaan barang atau jasa (trade of goodsContinue reading “E-commerce dan E-business Pengertian, Contoh, Keuntungan”
